TRANSFORMERS
Transformers are the architecture that made modern LLMs possible. Introduced by Google in 2017 with the paper “Attention is All You Need”, transformers replaced earlier sequential models (like RNNs and LSTMs) by allowing models to attend to all parts of the input at once.
Instead of reading left-to-right like a sentence, a transformer model uses a mechanism called self-attention to determine which parts of the input are relevant to each other. This lets it understand relationships between words, phrases, and even entire paragraphs — regardless of their order.
Transformers are also highly parallelizable, meaning they can be trained faster and on more data. This is a big reason why LLMs like GPT can scale to hundreds of billions of parameters.
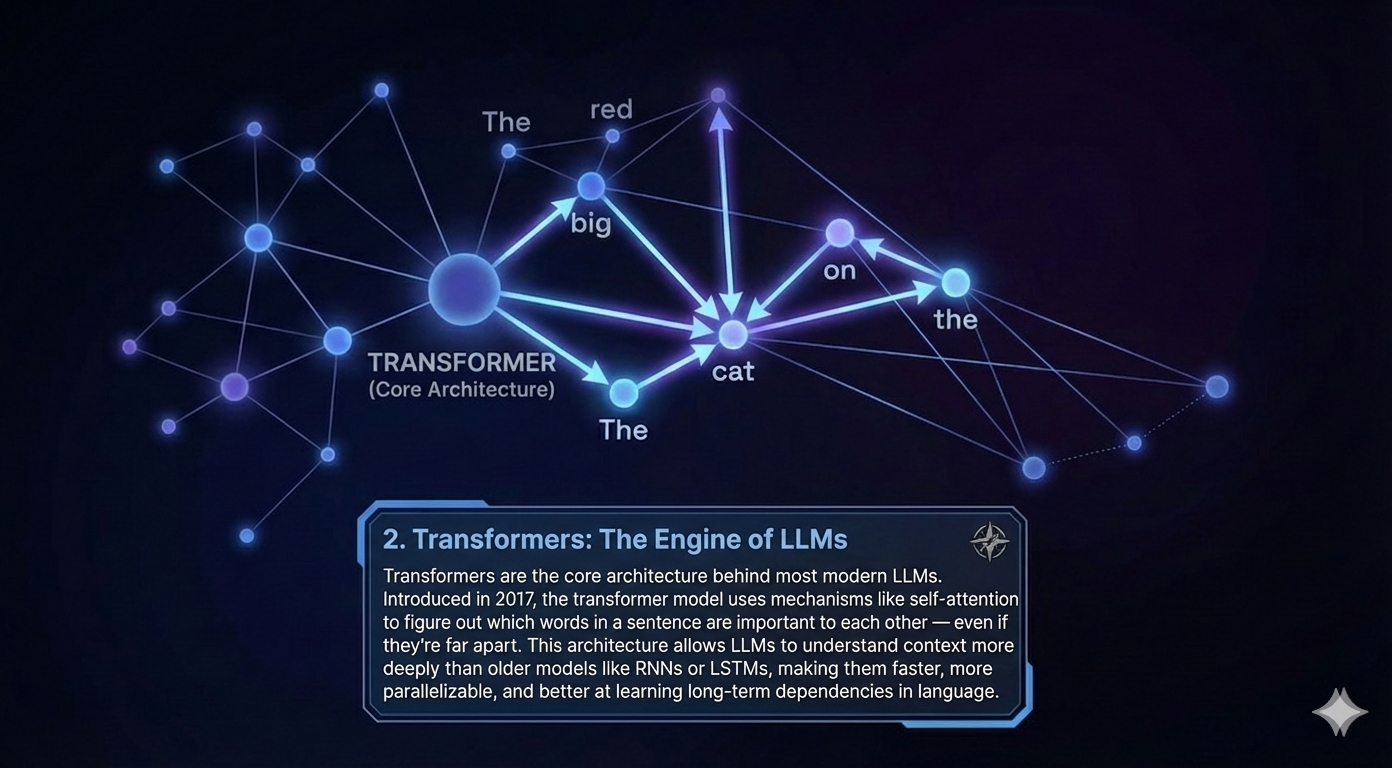
Engineering lens: Self-attention lets a model look at all parts of the input at once — not just one word at a time.
Memory trick: Transformers attend to everything — like giving equal attention to every part of the sentence.
What to remember
- “Attention is all you need”: that’s the key idea behind transformers.
- Self-attention: the model learns what to focus on across the whole input.
- Parallelization: train faster, scale bigger.